
Putting together a disaster recovery plan isn't about ticking boxes on a checklist. It's a living strategy that moves your company from reactive chaos to proactive resilience, ensuring you're ready for anything. The whole process boils down to a few core actions: analyzing business impacts, defining your recovery goals, picking the right strategy, writing it all down, and testing it relentlessly.
It’s easy to think of a disaster recovery (DR) plan as just another IT document—something you create once, file away, and hope you never need. But that mindset misses a critical truth: disruptions aren't a matter of if, but when. From simple hardware failures to sophisticated cyberattacks, the threats that can bring your operations to a grinding halt are more common than you might think.
The first step toward true resilience is to stop seeing disaster recovery as an IT problem and start treating it as a core business survival strategy. It’s about making sure your company can still serve customers, protect its reputation, and keep revenue flowing, even when things go sideways. A well-crafted plan is your operational lifeline.
The days of treating outages as rare, once-in-a-blue-moon events are long gone. In fact, a recent survey found that 100% of organizations lost revenue due to IT outages. Today, companies face an average of 86 outages every year.
It gets even more alarming: 55% of businesses report weekly disruptions, and 14% deal with them daily. These aren't just minor hiccups; they are direct, recurring threats to your bottom line.
A solid DR plan is built on four fundamental pillars:
Creating a robust plan is a foundational piece of comprehensive disaster preparedness for businesses, making sure your operations can weather any storm. For more targeted advice, check out our guide to building a small business disaster recovery plan. It provides a practical framework to build a plan that actually performs when you need it most.

Before you can sketch out any kind of recovery strategy, you first have to know what you’re protecting—and what you’re protecting it from. This is where a Business Impact Analysis (BIA) comes in. It's the foundational step where you pinpoint your most critical operations and get brutally honest about what happens if they go down.
This isn’t about abstract threats; it’s about confronting real-world scenarios.
What’s the fallout if your main sales server dies during the last week of the quarter? Or if a regional power outage knocks your local systems offline for 48 hours? A BIA forces you to map these dependencies and calculate the tangible costs of downtime, from lost revenue and reputational damage to regulatory fines.
This process is far more than a technical inventory. It's a business-centric evaluation that forces you to prioritize, because not all systems are created equal. Your customer-facing e-commerce platform almost certainly has a higher recovery priority than an internal development server.
The goal here is to build a clear hierarchy of your business functions. Start by identifying the core processes that generate revenue and deliver value to your customers. From there, list the specific applications, data, and infrastructure that keep them running.
You’ll need to consider a mix of internal and external threats that could throw a wrench in the works. These usually fall into a few key categories:
Once you have this list, you can start to quantify the potential damage of each disruption. What’s the financial cost per hour for your main application being offline? The answers you find become the bedrock of a truly smart disaster recovery plan.
Key Takeaway: A thorough Business Impact Analysis provides the data-driven rationale for your entire disaster recovery strategy. It ensures you invest your resources in protecting the assets that matter most to your business's survival and success.
The need for this analysis goes far beyond your company’s four walls. On a global scale, the economic stakes are enormous. When you factor in cascading ecosystem effects, disaster costs now exceed $2.3 trillion annually. This reality makes proactive risk assessment and resilient infrastructure non-negotiable parts of modern financial planning. You can explore more of the data behind this global impact in the United Nations' Global Assessment Report 2025.
Seeing this broader picture helps frame your BIA not just as an internal checklist but as a critical contribution to economic resilience. By understanding the true cost of downtime, you can confidently justify the investment needed to build a plan that actually works when you need it most.
Once your Business Impact Analysis is done, you've got a solid, prioritized list of what matters most. Now it's time to turn those priorities into real, measurable targets. This is where two of the most critical metrics in business continuity come into play: Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Think of RTO as the stopwatch. It’s the absolute maximum time a specific system can be down before it starts causing serious harm to your business. It's your hard deadline for getting things back up and running.
RPO, on the other hand, is all about your data. It defines the maximum amount of data—measured in time—you can afford to lose. This number directly dictates how often you need to be backing everything up.
These aren't just abstract IT terms; they're the direct translation of business risk into concrete goals for your tech team.
An RTO of one hour means the clock is ticking, and the team has exactly 60 minutes to restore a service. An RPO of 15 minutes means that if the worst happens, you'll lose no more than a quarter-hour's worth of data.
Let’s put this into context for an accounting firm:
Setting these values requires an honest conversation between department heads and your IT folks. The lower you set your RTO and RPO, the more complex and expensive your disaster recovery solution will be. The trick is to find that sweet spot that protects the business without breaking the bank on systems that can wait. For firms managing financial data around the clock, understanding these nuances is everything. You can learn more about protecting these applications in our guide to cloud hosting for QuickBooks.
By setting distinct RTO and RPO values for each application, you create a strategic framework for your disaster recovery plan. This ensures your most valuable resources are directed toward protecting the systems that have the biggest impact on your bottom line.
The chart below shows a common problem many businesses run into: the gap between what they hope their recovery times will be and what they actually are. It's a great visual reminder of why realistic planning is so important.
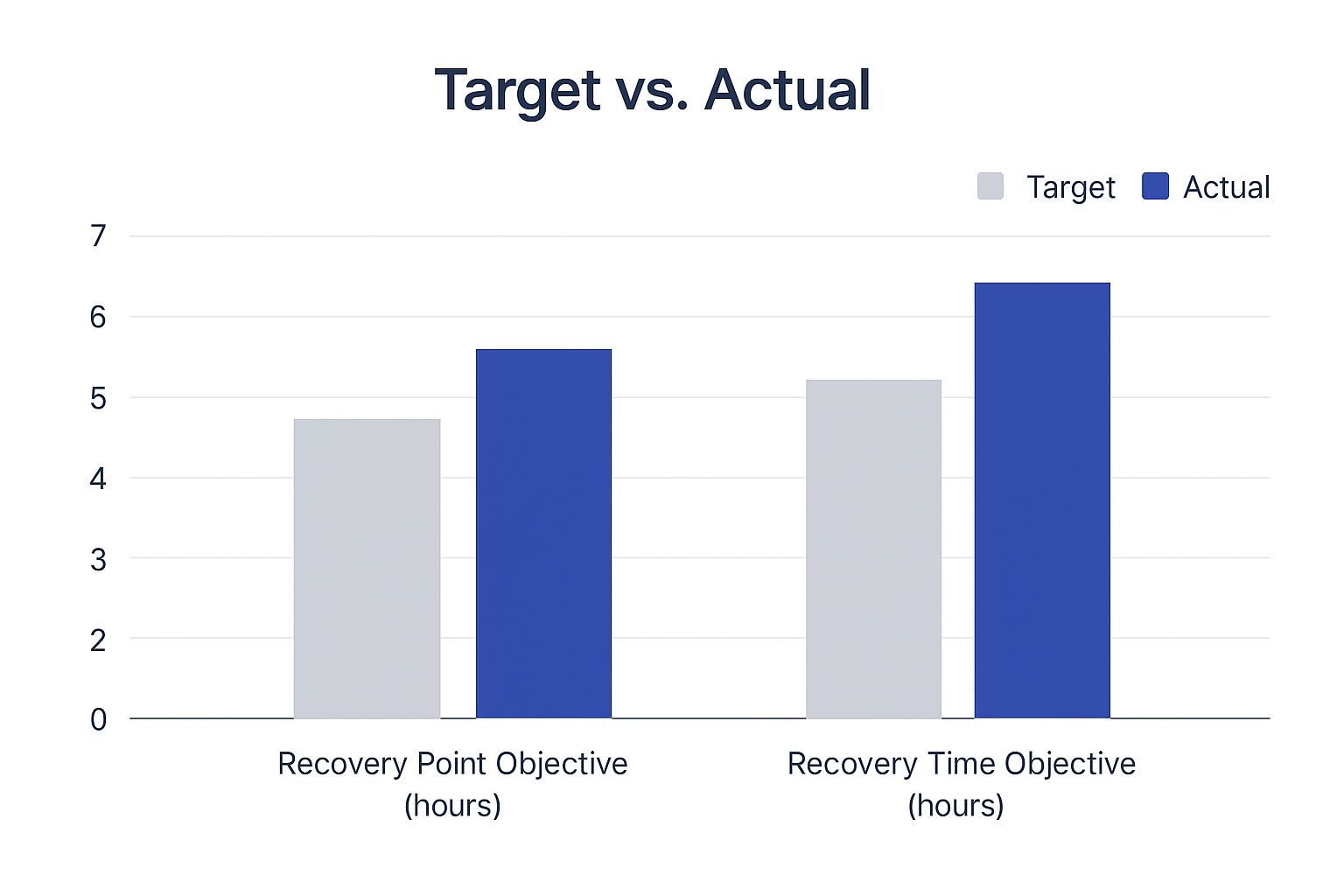
This gap between target and actual recovery times is exactly why you need to test your plan rigorously. It’s better to discover a shortfall during a drill than during a real disaster.
To help you get started, this table illustrates how RTO and RPO targets might look for different types of systems within a typical business. It's a great way to visualize how a system's importance directly impacts its recovery goals.
This table illustrates how RTO and RPO values differ based on a system's criticality to business operations, helping organizations prioritize their recovery efforts.
| Business System | Criticality Level | Example RTO | Example RPO | Recovery Strategy Implication |
|---|---|---|---|---|
| E-commerce Website | Mission-Critical | < 15 Minutes | < 5 Minutes | Requires automated failover and real-time data replication. |
| CRM/Sales Platform | Business-Critical | 1–4 Hours | 1 Hour | Needs frequent backups (hourly) and a warm standby site. |
| Internal Email Server | Business-Critical | 4–8 Hours | 4 Hours | Regular backups to a secondary location are sufficient. |
| HR/Payroll System | Important | 24 Hours | 24 Hours | Daily backups to cloud storage will meet the need. |
| Development/Test Server | Non-Critical | 48-72 Hours | 1 Week | Weekly backups are adequate; recovery can be scheduled. |
Notice how the recovery strategy becomes less intensive as the RTO and RPO increase. This tiered approach is the key to creating a plan that is both effective and affordable.
One of the smartest moves you can make is to tier your applications based on their RTO and RPO. This lets you build a recovery strategy that's perfectly tailored to your real-world needs without overspending.
This tiered method, driven by your BIA, ensures you're not paying for instant, five-minute recovery on an application that can comfortably wait 24 hours. It’s the crucial step that connects your high-level business analysis to the practical, technical side of your recovery plan.

Now that you’ve pinned down your RTO and RPO targets, it’s time to move from planning to action. This is the part where you pick the actual strategies and tools that will form the backbone of your disaster recovery plan. The right choice is always a balance between the recovery goals you just set, your budget, and the level of risk you’re comfortable with.
There's a whole spectrum of options out there, from simple cloud backups to highly complex, always-on systems. The real key is to match the solution to the need. Not every application requires the same level of protection.
A startup, for instance, might be perfectly fine relying on straightforward cloud backups for most of its data. It's a cost-effective and completely valid approach for systems that aren't mission-critical. On the flip side, a financial services firm processing transactions 24/7 will absolutely need a robust, high-availability solution to hit its near-zero RTO and RPO goals.
When you start looking at recovery infrastructure, you'll hear about three main models: cold, warm, and hot sites. Each one offers a different trade-off between recovery speed and cost, so understanding the distinction is crucial.
Your choice between a cold, warm, or hot site really comes down to your RTO. If your business can't afford to be down for more than a few minutes, a hot site is non-negotiable. If you can handle a day of downtime, a warm site might be the perfect balance of cost and speed.
Let's be honest—building and maintaining a physical recovery site is a massive undertaking, both financially and logistically. This is where Disaster Recovery as a Service (DRaaS) completely changes the game. With DRaaS, providers like Cloudvara manage the entire recovery infrastructure for you in the cloud.
In a DRaaS model, your systems are replicated to a secure cloud environment. If something takes down your primary site, you just failover to the cloud replica and keep your business running with minimal disruption. It’s a way to get hot-site-level recovery speeds for a fraction of what it would cost to build your own.
This is a huge advantage for businesses looking to simplify their IT overhead. When you migrate your on-premise servers, you’re not just getting a backup; you’re adopting a full-fledged business continuity solution. Getting expert help with https://cloudvara.com/cloud-migration-services/ makes the switch seamless and ensures your DR plan is built on a solid foundation from the start.
As you select your tech, don't forget about communication. Keeping your team connected is vital, so look into tools like Radio over IP (RoIP) for disaster recovery to maintain contact when traditional lines are down.

A disaster recovery plan that lives only in an expert’s head or on a forgotten server is completely useless during a real crisis. The goal is to create a living document that is so clear and straightforward that anyone on your team can grab it and follow the steps under extreme pressure.
Think of it less like a technical manual and more like a blueprint for resilience. This document becomes the single source of truth that guides your team through the chaos, ensuring every decision is deliberate and every action is coordinated. Without it, you’re just improvising—and that’s a recipe for prolonged downtime and costly mistakes.
To make your plan truly actionable, it needs to be broken down into clear, logical sections. Forget the jargon and overly technical language; clarity is your top priority. Anyone, from a senior engineer to a non-technical manager, should be able to instantly understand their role and what to do next.
Your documented plan should always include these core elements:
This structure ensures that during a high-stress event, there's no confusion about who does what or how to get it done.
A great disaster recovery document is designed for the worst-case scenario. It assumes key people might be unavailable and primary communication channels could be down. Simplicity and accessibility are its greatest strengths.
The most detailed plan in the world is worthless if you can’t get to it when you need it most. If your only copy is sitting on a server that just went down, you have a very serious problem. You absolutely must store multiple copies in different, secure locations to guarantee access.
Best practices for accessibility include:
Effectiveness also varies widely. Recent data shows that about 33% of businesses admit their disaster recovery plans were ineffective during outages, and only 30% have a thoroughly documented plan in the first place. Interestingly, just 32.1% have plans that specify which applications and business elements to prioritize. You can read more on these disaster recovery statistics to see how a well-documented plan puts you ahead.
Ultimately, this document is a key part of your overall business continuity in the cloud strategy, ensuring that your recovery efforts are organized, efficient, and successful.
Creating your disaster recovery plan is a huge step, but it’s definitely not the finish line. A plan that just sits on a shelf collecting dust is almost as dangerous as having no plan at all. True business resilience comes from treating disaster recovery as a living, breathing process of testing, learning, and improving.
This isn't a one-and-done task. It's a continuous cycle that keeps your plan relevant as your business evolves. You'll adopt new technologies, team members will come and go, and business priorities will shift. Without regular tune-ups, the plan you wrote last year might completely miss the mark on the risks you face today.
Testing is where theory meets reality. It's the only real way to find weaknesses, spot gaps in your procedures, and build your team’s confidence long before an actual crisis hits. You wouldn't expect a fire department to show up to a five-alarm fire without ever running a drill, right? The same logic absolutely applies here.
There are a few solid ways to test your plan, each with its own level of intensity and commitment:
Running these exercises regularly is critical. For a deeper dive, our complete guide on business continuity plan testing lays out more in-depth strategies to make sure you're truly ready.
The real magic of testing happens after the drill. What you do with the results is what counts. After every test, run a thorough post-mortem to analyze what went well and—more importantly—what didn't. Did a key team member lack the right permissions? Was a recovery step confusing?
A failed test isn't a failure of the team; it's a successful discovery of a weakness you can now fix. Every single issue you uncover during a drill is one less problem you’ll have to solve during a real disaster.
Use these findings to update your documentation right away. Refine your checklists, update contact info, and schedule more training where it's needed. This feedback loop is what turns your plan from a static document into a dynamic, battle-tested strategy that genuinely protects your business. Get these tests on the calendar at least once a year, or anytime you make a major change to your IT environment. A well-tested plan is what separates a controlled recovery from chaotic scrambling.
A resilient disaster recovery plan is built on a foundation of reliable infrastructure and expert support. Cloudvara provides a secure cloud hosting environment with automated daily backups and 24×7 assistance, ensuring your business is prepared for anything. See how our platform can simplify your DR strategy by visiting https://cloudvara.com.





